TL;DR
开篇提到了good design,那如何评价一个设计是不是好的设计呢?其中很重要的一点就是:具有良好的扩展性。
如何让自己的设计具有良好的扩展性呢?首先想到的就是插件机制了。没错,就是插件机制,像Eclipse、IntelliJ IDEA这些开发软件都支持大量的插件。
Java本身提供了一种叫SPI(Service Provider Interface)的插件机制,在JDK中大量使用,如JDBC、JNDI等。
像Spring、Dubbo这些开源框架也是基于SPI机制实现可扩展性,只不过,Spring和Dubbo框架自身的SPI分别在JDK的SPI基础上进行了扩展,这些后续在对这两个框架的源码分析中会进行比较,这篇先分析JDK提供的SPI机制。
本篇内容大纲如下:
- 什么是SPI
- SPI解决了什么问题
- JDK源码中如何使用SPI
- 基于SPI机制的实现示例
- JDK的SPI有什么限制吗
首先我们需要了解下什么是SPI。
0x01 什么是SPI?
维基百科对SPI的定义是:
Service Provider Interface (SPI) is an API intended to be implemented or extended by a third party. It can be used to enable framework extension and replaceable components.
简单的说SPI是提供给第三方用以实现或扩展的API,它可以被用于框架暴露出扩展点实现组件的替换。
SPI的定义中有Service、Provider、Interface三个名词,那什么是Service,什么是Provider,接口的用途是什么呢?
Service(服务):是指一组众所周知的接口或类(通常是抽象类);Service Provider(服务提供者):是指Service的一个特定实现,服务提供者通常会实现服务接口(或继承服务抽象类);
其实,除了服务和服务提供者,还有一个角色就是服务加载器(Service Loader),它是专门负责加载某一类插件的,这个后面会介绍。
服务提供者可以打成jar包之后放到Java平台的扩展目录下来进行安装,也可以放置到程序的classpath下或其它一些特定于平台的方式来让服务提供者变得可用。(我们通常是通过classpath的方式来使用)
出于加载的目的,一个服务通常为一个接口或一个抽象类(非抽象类也可以使用,但不推荐)。一个服务提供者可以是一个或多个类,这些类之间相互协作来实现服务接口,以提供服务的能力。不同的服务提供者的具体实现细节不同,通常不同的服务提供者会提供差异化的服务。
服务提供者的唯一要求就是必须要有无参构造函数,这样才能在加载时被正常的实例化。
既然可以有不同服务提供者,那系统如何识别多个不同的服务提供者呢?
服务提供者是通过放置在资源目录META-INF/services下的一个提供者配置文件来标识的。这个配置文件的名称是服务接口的全路径名称(即:包名+类名),配置文件的内容是服务提供者的全路径名称的列表,每行一个,其中空格、制表符和空行都会被忽略,注释的符号为#,注释符号后面的所有内容都会被忽略;最后,文件的编码必须是UTF-8格式。
如果一个服务提供者在多个配置文件中配置,或是在同一个配置文件中配置了多次,重复的项会被忽略。
另外,服务提供者的配置文件和二进制文件可以不在同一个jar包中,只需要保证配置文件和二进制文件可以被同一个类加载器(Class Loader)加载即可。
服务加载器(Service Loader)使用延迟加载的方式加载服务提供者,换句话说,只有在真正使用到某个具体的服务提供者时,该服务提供者才会被实例化。并且,实例化后的服务提供者实例会被缓存,服务加载器提供了reload()方法来清除缓存。
0x02 SPI解决了什么问题
上面对服务(Service)、服务提供者(Service Provider)和服务加载器(Service Loader)进行了介绍,我们知道服务提供者是真正的服务实现者,而且服务加载器可以加载各种实现了同一服务的不同的服务提供者。
为什么要支持对一个服务支持不同的服务提供者呢?从面向对象设计原则的角度来看,它是符合了开闭原则(OCP)的,框架的处理逻辑只依赖于一个抽象(SPI这里可以是接口或抽象类),具体的实现变成了一种可拔插的方式,系统变得更松散,当系统需要支持某种服务的另一种实现时,不用修改系统本身,增加一种具体实现(服务提供者)即可,增强了系统的可扩展性。
再看维基百科上对SPI的定义中有一句话:被用于框架暴露出扩展点实现组件的替换。
也就是说,SPI一般用于把框架的扩展点暴露给开发者,让开发者可以实现组件的替换。但实际上并不只是局限于替换,也可以是扩展服务能力,具体取决于框架的逻辑实现,这个后面举例说明。
无论是替换还是扩展,其实本质上就是让我们的系统更加的向面向对象的设计目标靠拢:高内聚,低耦合。通过满足开闭原则,提供框架本身的可扩展性,这就是SPI本身想解决的问题。
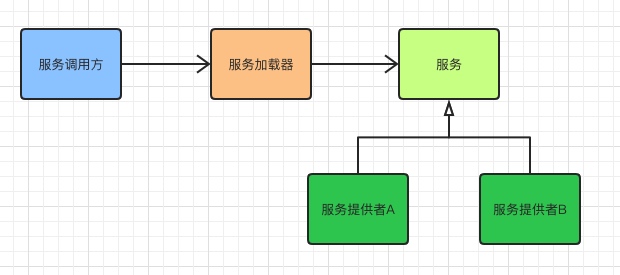
上图是服务、服务提供者、服务加载器之间的关系图。
0x03 JDK中如何使用SPI
JDK在很多地方都使用了SPI机制来提升扩展能力,维基百科中列举的有下面这些:
- Java Database Connectivity
- Java Cryptography Extension
- Java Naming and Directory Interface
- Java API for XML Processing
- Java Business Integration
- Java Sound
- Java Image I/O
- Java File Systems
对我们而言,接触最多的当属第一个,也就是JDBC了,我们就看一下JDBC是如何使用SPI的吧。
/**
* @author zhaoyang
*/
public class TestJdbcSpi {
private Connection conn;
@Before
public void setUp() {
try {
Class.forName("org.hsqldb.jdbcDriver");
conn = DriverManager.getConnection("jdbc:hsqldb:mem:test", "sa", "");
ScriptRunner sr = new ScriptRunner(conn);
sr.setLogWriter(null);
sr.runScript(Resources.getResourceAsReader("create-schema.sql"));
sr.runScript(Resources.getResourceAsReader("init-data.sql"));
} catch (Exception e) {
e.printStackTrace();
}
}
@Test
public void testJdbcSpiByHsqldb() {
SqlRunner sr = new SqlRunner(conn);
try {
List<Map<String, Object>> results = sr.selectAll("select * from user");
assertTrue("user data not found", results.size() > 0);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
conn.close();
} catch (SQLException e) {}
}
}
}
上图是使用HSQLDB进行测试的例子。
我们来分析一下这里哪里用到了SPI。
@Before标的方法是junit运行测试方法的前置方法,它会在每个@Test测试运行之前运行一次,我们这里只有一个@Test方法,并且,HSQLDB是内存数据库,所以这么写没有关系。
在setUp方法中我们首先调用了Class.forName("org.hsqldb.jdbcDriver")这一行代码,它的作用是将指定的类加载进来(加载的是Class),这个过程会强制ClassLoader加载Class,同时会执行static代码块;其实,把这一行注释掉,代码也是可以正常运行的(前提是在JVM的classpath下能加载到org.hsqldb.jdbcDriver这个类,以及它所依赖的其它类),原因等下再说。
接下来,通过DriverManager.getConnection("jdbc:hsqldb:mem:test", "sa", "")就能获取到Connection对象了,它怎么知道我要哪个对象呢?这里就用到了SPI机制,查看DriverManager的源码,我们可以看到在它的类中有一个静态代码块:
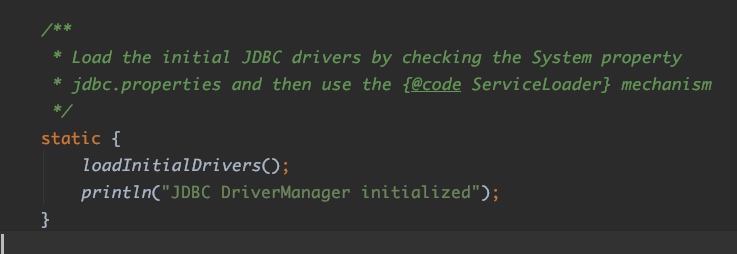
这个代码块在DriverManager类加载的时候就会被调用,里面有一个loadInitialDrivers()方法:
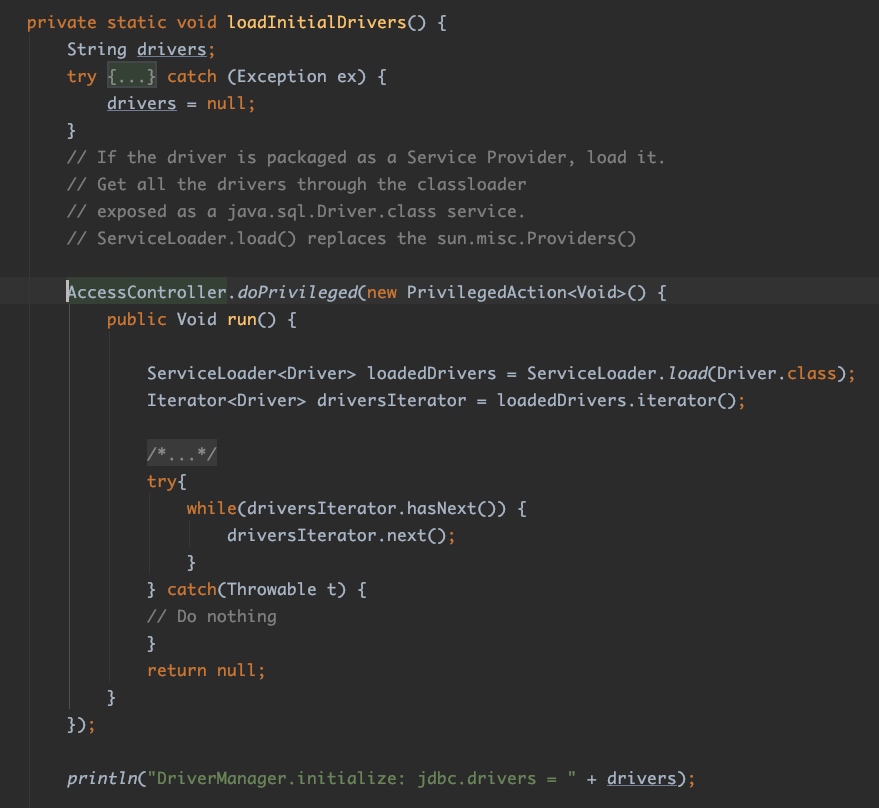
其中关键的一行是:ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);。
这里调用了服务加载器来查找所有Driver.class的服务提供者,这个Driver.class是java.sql.Driver,是一个接口,定义了服务要实现的方法。
服务加载器会把所有查找到的服务提供者全部加载进来(上图中的while循环)。
这里特别注意一下:loadedDrivers.iterator(),跟进去ServiceLoader类,你会发现,这里返回的Iterator对象是ServiceLoader的一个内部匿名实现:
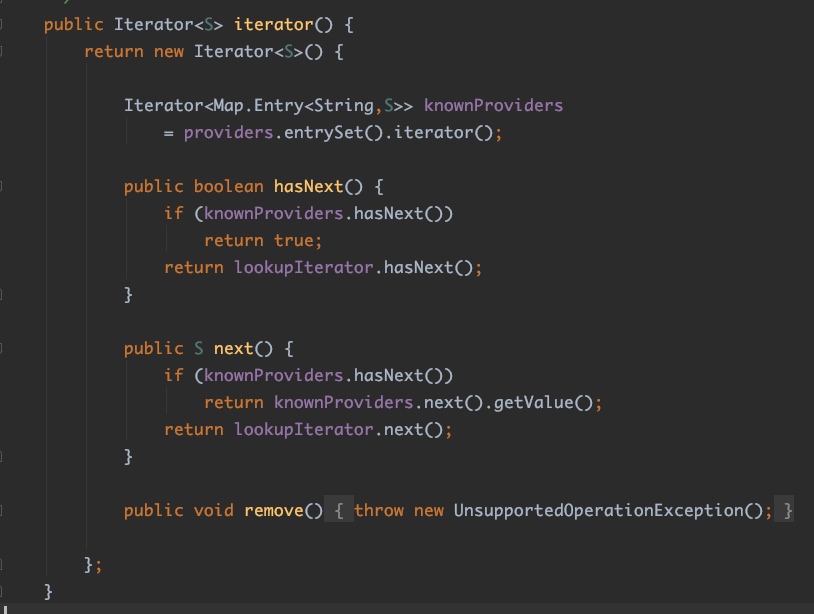
在随后的while循环时,里面调用的driversIterator.next();实际就是调用的上面图片中的next()方法,这个next()方法的实现,它在交替的通过延迟加载的方式来处理服务提供者。本质上next()方法都会触发到LazyIterator#nextService()方法:
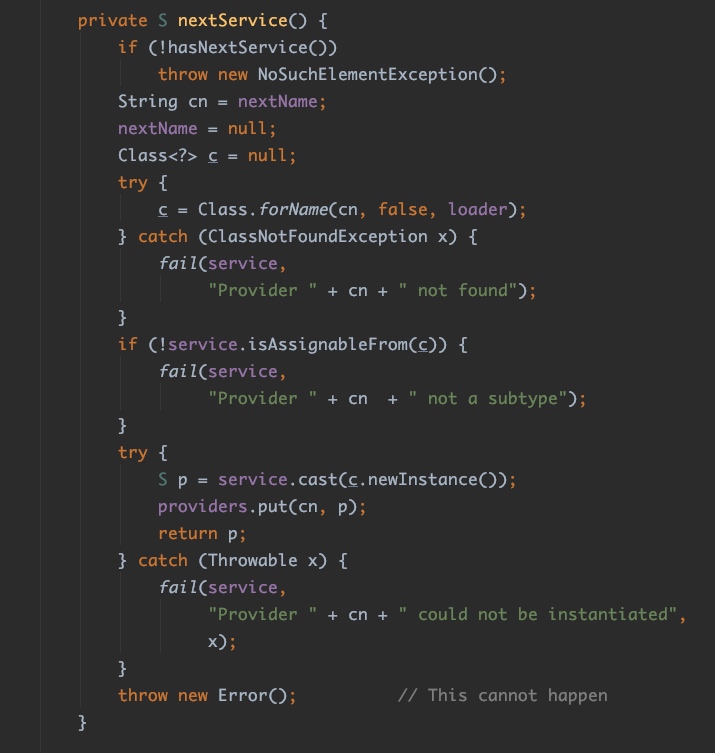
而这个方法中,有一行代码是在调用:Class.forName(cn, false, loader);,这不就是我们前面测试代码中给注释掉的那行代码吗?原来,ServiceLoader在加载Provider时,默认会去把对应的服务的Class加载进来,这个过程会触发对应的Class的静态代码块,为什么要强调触发静态代码块呢?我们后面再分析。
当我们的测试用例在启动的时候,在调用DriverManager类的方法之前,DriverManager会先去classpath下搜索所有java.sql.Driver的服务提供者,这里会扫描classpath下的jar包,搜索服务配置文件,这个配置文件的路径是在资源目录META-INF/services下,文件名称在这里应该是java.sql.Driver,我们查看项目工程的依赖路径下,因为我们使用的是HSQLDB,所以在项目依赖中,我们会添加hsqldb-xxx.jar的依赖(这里的xxx是版本号)。
我们点开hsqldb-xxx.jar,我们可以看到:
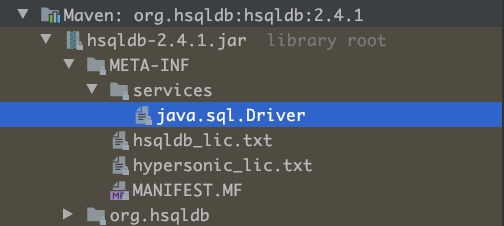
这个jar包下面,确实有对应的路径和文件,打开文件,可以看到里面的内容是:
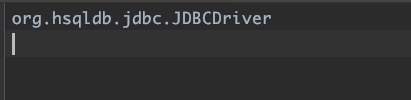
按照前面的约定,这个文件的内容就是全路径的服务提供者名称,我们就可以打开这个类来看一下就会发现,org.hsqldb.jdbcDriver实现了java.sql.Driver类。
到这里为止,感觉确实是通过SPI的方式加载了HSQLDB的驱动,如果我的classpath下有多个厂商提供的驱动会怎样呢?
我们在classpath下加上h2内存数据库的依赖:
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.4.200</version>
<scope>test</scope>
</dependency>
然后同样在项目的依赖下找到h2-xxx.jar的jar包,点开,可以看到:
`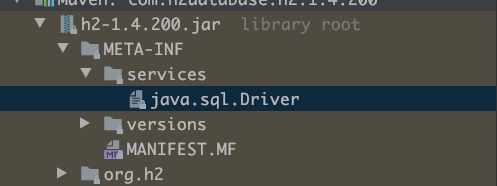
完全符合JDBC对第三方扩展的规范,这里java.sql.Driver文件的内容为:
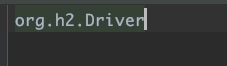
打开这个类文件,可以发现org.h2.Driver也同样实现了java.sql.Driver接口。
到现在为止,我们清楚Service、Service Provider和ServiceLoader三者的关系,但我们还是不清楚,一个第三方的java.sql.Driver实现具体是怎么被DriverManager发现的,现在还只有ServiceLoader知道了这些第三方实现的存在。
我们再看一下DriverManager#getConnection()方法(参数去掉了),这里面有一段循环处理已注册的驱动的代码:
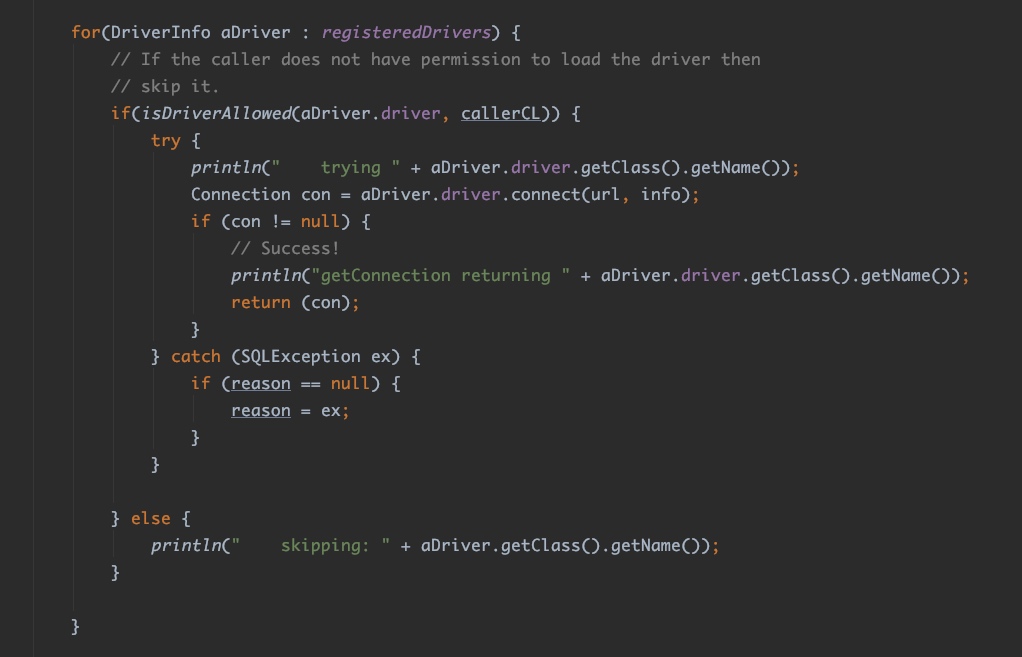
原来DriverManager循环查找已经向自己注册过的Driver类,那第三方的驱动是什么时候,又是如何向DrvierManager注册的呢?我们清楚了这一些,整个流程才全部串联起来了。
前面一直在强调Class#forName()方法会触发对应类的静态代码块,那就可以猜测一下,是不是第三方的实现在实现类中有一段静态代码块专门来向DrvierManager注册自己,这样在ServiceLoader加载到自己时,通过Class#forName()方法就可以触发自己的注册流程了(这就是为什么前面的测试用例,注释了Class#forName()那行代码,测试用例也能正常运行的原因,这是JDBC 4.0新增的功能)。
于是,我们去查看前面的两个驱动类:
在org.hsqldb.jdbc.JDBCDriver类中有这样一段静态代码块:
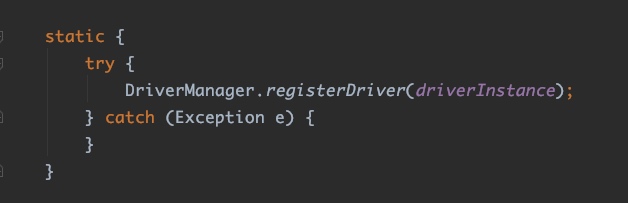
同样,在org.h2.Driver类中有这样一代静态代码块:
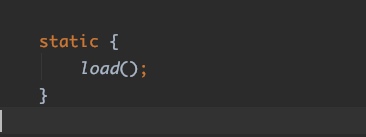
对应的load()方法:
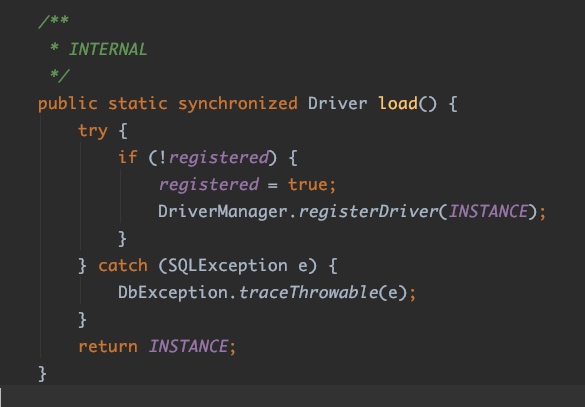
果然是这样啊,第三方的实现在自己的服务提供者实现类中,增加一个静态代码块,这个代码块中通过调用DriverManager#registerDriver()方法来把自己的实例注册给DriverManager。
这两个都是内存数据库,我想知道我们常用的MySQL是不是也是这样,于是,把MySQL的JDBC驱动添加到项目的依赖中,然后去找到资源配置文件里面的类,打开:
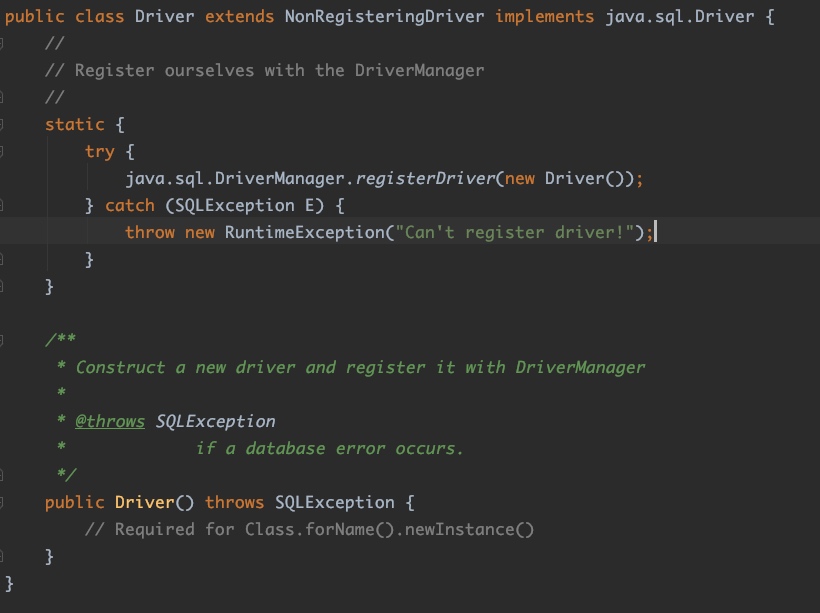
结果既不惊喜也不意外,非常直接。
至此,我们已经研究了java.sql.Driver的多个扩展实现了,你再看MySQL、Oracle等数据库的驱动jar包,也会发现它们也都符合JDBC对第三方的扩展规范。
现在,我们的classpath上有了java.sql.Driver的多个服务提供者,那会不会出问题呢?
按照前面定义里讲的话是不会出问题的,因为只有你的代码使用到某一个具体的服务提供者的时候,它才会去加载它,同时存在多个是不会影响的。
我们试一下:
public class TestJdbcSpi {
private Connection conn;
@Test
public void testJdbcSpiByHsqldb() {
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
conn = DriverManager.getConnection("jdbc:hsqldb:mem:test", "sa", "");
System.out.println(conn.getClass().getName());
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
conn.close();
} catch (SQLException e) {}
}
}
@Test
public void testJdbcSpiByH2() {
try {
Class.forName("org.h2.Driver");
conn = DriverManager.getConnection("jdbc:h2:mem:test", "sa", "");
System.out.println(conn.getClass().getName());
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
conn.close();
} catch (SQLException e) {}
}
}
}
执行整个测试类,两个测试方法被执行,分别输出如下:

两个测试方法各自正确的加载了各自需要的驱动,并打印出了各自获取到的连接对象的类名。
到这里,JDK源码中使用SPI的分析就结束了。
通过上面的实践,我们可以知道,对于一个Service,我们可以实现很多不同的Service Provier,这些不同的Provider是可以共存在同一个classpath下的,而且,我们要扩展一种新的Service Provider能力时,不用去修改原来的代码,只需要按照约定的规范去做一个新的Provider即可,最后把它放到程序能加载到的地方(通常是程序的classpath,但并不只有这一个位置可以放,具体有哪些路径和jvm的加载机制有关),这样我们的程序的可扩展性就大大的增强了。
0x04 基于SPI机制的实现示例
现在我们清楚了整个SPI运行的流程,以及各个不同的角色的职责分工,下面应该动手实践了。
首先,定义一个服务接口:
public interface Dictionary {
/**
* Get the definition of the input word.
* @param word the query word
* @return the definition of the word
*/
String getDefinition(String word);
}
然后定义两个不同的服务提供者:
public class ExtendedDictionary implements Dictionary {
private SortedMap<String, String> map;
public ExtendedDictionary() {
System.out.println("ExtendedDictionary loaded");
map = new TreeMap<>();
map.put("xml", "a document standard often used in web services, among other things");
map.put("REST", "an architecture style for creating, reading, updating, " +
"and deleting data that attempts to use the common " +
"vocabulary of the HTTP protocol; Representational State " +
"Transfer");
}
@Override
public String getDefinition(String word) {
return map.get(word);
}
}
public class GeneralDictionary implements Dictionary {
private SortedMap<String, String> map;
public GeneralDictionary() {
System.out.println("GeneralDictionary loaded");
map = new TreeMap<>();
map.put("book", "a set of written or printed pages, usually bound with " +
"a protective cover");
map.put("editor", "a person who edits");
}
@Override
public String getDefinition(String word) {
return map.get(word);
}
}
服务提供者的构造函数有一行代码会打印一行信息,这个信息会在服务提供者被实例化时输出,加上这一行代码的目的是想验证服务提供者被加载的次数。
然后实现服务的调用方:
public class DictionaryService {
private ServiceLoader<Dictionary> serviceLoader;
/**
* Not allowed create DictionaryService instances from other place.
*/
private DictionaryService() {
// load all Dictionaries when initialized DictionaryService.
loadServices();
}
public static DictionaryService getInstance() {
return LazyHolder.SERVICE;
}
/**
* Singleton instance holder
*/
private static class LazyHolder {
private static final DictionaryService SERVICE = new DictionaryService();
}
/**
* ServiceLoader load all Dictionary.class implements
*/
private void loadServices() {
serviceLoader = ServiceLoader.load(Dictionary.class);
}
/**
* Find definition from all loaded dictionaries.
* If found, return the first matched definition,
* otherwise, return null.
*
* @param word the query word.
* @return The first result find from all Dictionaries.
*/
public String getDefinition(String word) {
String definition = null;
try {
// serviceLoader.reload();
Iterator<Dictionary> dictionaries = serviceLoader.iterator();
while (definition == null && dictionaries.hasNext()) {
Dictionary d = dictionaries.next();
definition = d.getDefinition(word);
}
} catch (ServiceConfigurationError error) {
definition = null;
error.printStackTrace();
}
return definition;
}
}
这里的服务调用方使用了单例模式,确保系统只创建一个实例。这里定义了一个getDefinition方法,这是真正被系统使用的方法,本质上,这里是定义的服务Dictionary被如何使用的逻辑。
从上面的代码我们可以看到,对于输入的word,我们会对服务加载器所加载到的所有的服务提供者都会去调用它们所实现的getDefinition方法。这与java.sql.Driver的服务使用逻辑不太一样,java.sql.Driver是替换的思想,而我们这里是组合的思想,对于输入的word,如果没有查到对应的定义,只要还有服务提供者就会继续遍历下去,直到遍历完所有的服务提供者为止。
注释掉的那行:serviceLoader.reload()是用来验证ServiceLoader的缓存的。
然后就是测试代码了:
public class DictionaryApp {
/**
* Using <code>DictionaryService</code> to look up the word definition.
* @param dictService concrete look up service
* @param word the query word
* @return the definition of the word
*/
public static String lookup(DictionaryService dictService, String word) {
String output = word + ": ";
String definition = dictService.getDefinition(word);
if (definition == null) {
return output + "Cannot find definition for this word.";
} else {
return output + definition;
}
}
public static void main(String[] args) {
DictionaryService dictService = DictionaryService.getInstance();
System.out.println(lookup(dictService, "book"));
System.out.println(lookup(dictService, "editor"));
System.out.println(lookup(dictService, "xml"));
System.out.println(lookup(dictService, "REST"));
System.out.println(lookup(dictService, "not-exist"));
System.out.println(lookup(dictService, "book"));
}
}
在DictionaryApp的main()方法中,调用了两次lookup(dictService, "book"),目的是为了验证服务加载器会对每个特定的服务加载几次。
运行程序,得到输出:

可以看到,我们自己的实现和我们的预期一样执行。
另外,这里的示例,服务的定义、服务的两种不同实现,以及服务的调用分别是放在不同的工程下的,具体参考文末的示例代码链接的仓库代码。(本地运行需要先在项目根目录下执行mvn install,将包安装到本地仓库,否则可能会提示找不到jar包)
0x05 JDK的SPI有什么限制吗
到这里,关于JDK的SPI就全部讲完了,那这个SPI完美吗?有没有什么局限性呢?
JDK提供的ServiceLoader API很有用,但也有其局限性。
比如:
ServiceLoader是一个final类,不能被扩展,也就是说,我们没有办法去改变服务加载器的加载行为;- 当前的
ServiceLoader没办法在运行时加载新的服务提供者; - 我们也没有办法对
ServiceLoader增加Listener来监听一些感兴趣的变化事件等;
0x06 总结
到这里,我们把JDK的SPI机制完整的分析了一遍,并通过一个示例实践动手验证了它的一些约定等。
我们也清楚了SPI的目的是什么,有什么用处,如何使用等,未来,我们可以轻松的把这种扩展机制应用到我们的代码中,让我们代码的扩展能力更强。
同时,我们也知道JDK的SPI也有一些局限性,所以后面的Spring和Dubbo框架都在这个基础之上对SPI进行了增强,接下来会分析Spring中的SPI,然后再分析Dubbo的SPI,我个人觉得Dubbo的SPI是这三者中最美的。
好了,这一篇的内容到此就结束了,欢迎各种反馈和交流!